Spur AI Chat is a full-stack AI-powered customer support assistant built for e-commerce, featuring a React/TypeScript frontend and an Express/SQLite backend that routes conversations through OpenRouter's GPT-4o-mini. It demonstrates end-to-end LLM integration with persistent conversation history, a domain-specific system prompt, and a production deployment across Vercel and Render.
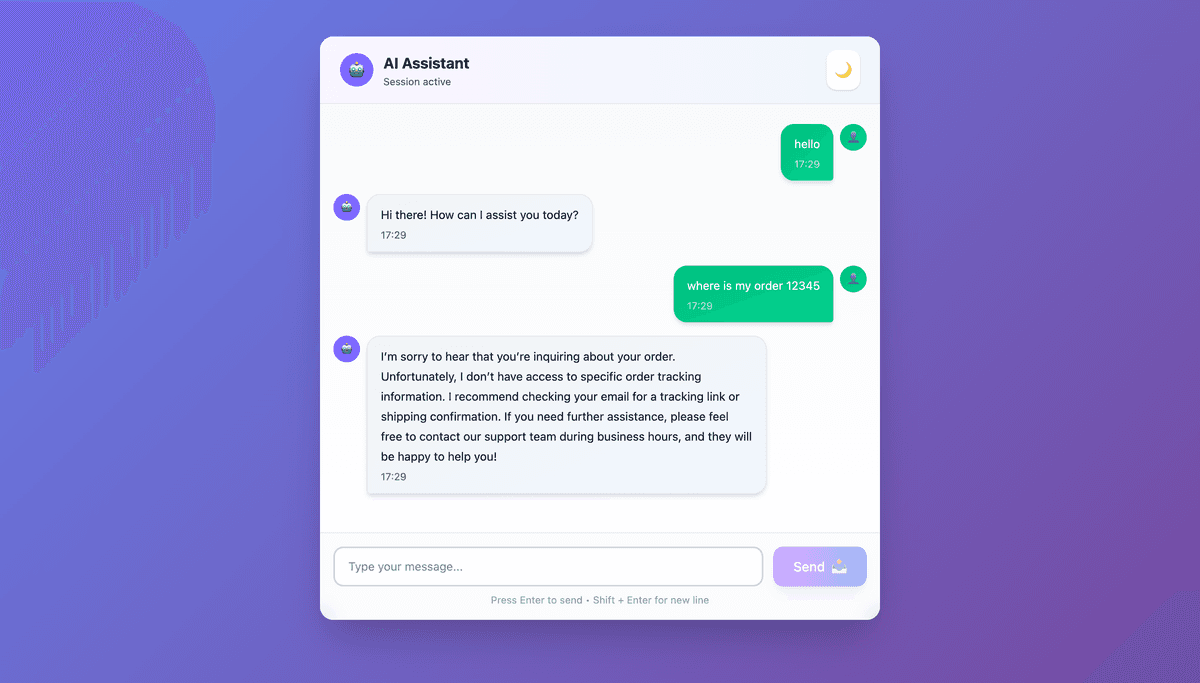
Spur AI Chat is a full-stack conversational AI application built as an intelligent support agent for a small e-commerce store. It handles customer inquiries around products, orders, shipping, returns, and refunds — all through a clean chat interface backed by a real LLM.
Small e-commerce businesses often can't afford 24/7 human support, yet customer inquiries are repetitive and time-sensitive. The goal was to build a working AI support agent that could handle common questions consistently, persist conversation history across sessions, and be deployable at near-zero cost.
The application is split into a React frontend and an Express backend, communicating over a REST API. Each user session gets a UUID-tracked conversation stored in SQLite. On every message, the backend retrieves the last 10 exchanges, prepends a domain-specific system prompt embedding the store's policies (shipping zones, return windows, refund timelines), and sends the full context to the LLM via OpenRouter. The response is stored and returned to the frontend.
Rather than building a FAQ database, store policies are embedded directly in the system prompt — a deliberate trade-off that simplifies the architecture while keeping the agent reliably on-brand.
Session persistence is handled by fetching conversation history from the backend on page load, with a localStorage fallback if the backend is unavailable.
Context window management: Sending the full conversation history on every request is expensive. A fixed sliding window of the last 10 messages was chosen to balance conversational continuity against token cost — a conscious trade-off that works well for support use cases where conversations are short.
Cross-origin deployment: With the frontend on Vercel and backend on Render, CORS had to be explicitly configured. ALLOWED_ORIGINS is set as an environment variable in production so the backend only accepts requests from the known frontend URL, without hardcoding it.
Cold starts on Render free tier: Render's free tier spins down after 15 minutes of inactivity, causing 30–60 second cold starts. This was documented and accepted as a known limitation for a portfolio/demo deployment.
main